My Blog Is Moving
· One min read
My blog is moving to LinkedIn, with a new focus - startup fundraising. see Founders OnChain Capital
My blog is moving to LinkedIn, with a new focus - startup fundraising. see Founders OnChain Capital
Building AI-powered workflows comes with many options, so it can feel overwhelming. The choice might come down to choosing something like n8n, which offers drag-and-drop automation and easily integrates with other tools, or MCP (Model Context Protocol), a standard for defining how LLMs interact with tools and data.
Both approaches have their strengths. Depending on what you’re trying to build, one might save you weeks of engineering time.
To understand this better, I'm breaking down where each one excels and struggles, and how to decide which one is the best fit for your project.
Most companies are still treating web analytics like it’s 2015. They set up GA4 or Adobe, tag their campaigns, and trust the dashboards to tell them how people discover and engage with what we publish. But LLMs have changed everything in the past year, and it’s quietly rewriting the rules of attribution.
LLMs are the new gateway to your website. Web users are asking questions in chat interfaces that pull in pieces of your content to help form answers. While great for brand visibility, it’s problmeatic for traditional analytics. Since these interactions often don’t fire the JavaScript that standard web analytics depends on, you have a flaw in your reporting.
Here's an example: Someone asks ChatGPT about the best way to calibrate lab equipment. The model finds an excerpt from your guide and follows up with a link. The user clicks it, skims a section, and leaves. In GA4, you’ll see either nothing at all or a tiny blip of Direct traffic you can’t attribute. Over time, that missing traffic adds up.
In the end, if you can’t measure LLM behavior, you can’t make informed decisions about what’s driving conversions.
You’ve probably noticed that some of your content seems to vanish into the void. It never seems to surface in search or meet with enthusiasm from your audience. It’s not bad luck: AI models that rank and retrieve content are particular about how they process what you write. If you don’t pay attention to how they work, your content will end up buried.
Here, i walk through the biggest issues that will keep your content from being found and understood by AI...and what you can do to fix them.
Building online authority requires chasing backlinks, tweaking keywords, and manually engaging multiple platforms just to stay visible. But that playbook is changing (who has the patience?). I'm putting togther a new system—the Embeddings-Powered Content Intelligence Engine to brings automation, semantic analysis, and smart content distribution together for the sake of LLM brand visibility.
Embeddings is at the heart of this system. These are vector-based representations of language that capture the meaning and context of words, not just their appearance. They help us understand why some content connects and spreads, while other posts fall flat.
Note: RAG is a technique that improves an LLM's capabilities by integrating them with external data sources.
RAG (Retrieval-Augmented Generation) systems can be used to simulate and test how LLMs retrieve content. They don't just probe what a model knows, but what it displays when someone asks a question.
If you’ve ever asked ChatGPT a question and found a competitor’s blog quoted back to you, you’re probably wondering how to get YOUR content into that response box.
Traditional SEO might help but is not the full answer. LLMs don’t crawl pages in the way search engines do. They embed them, converting your content into numerical representations. Its how they capture a site's meaning, tone, and topic relationships.
In other words, LLMs don't index your keywords, they interpret your concepts.
That’s why embedding analysis can be used to reverse engineer how AI models understand your site. You don't need to guess what they might say about your content, you can look directly at the data they're using to generate those answers.
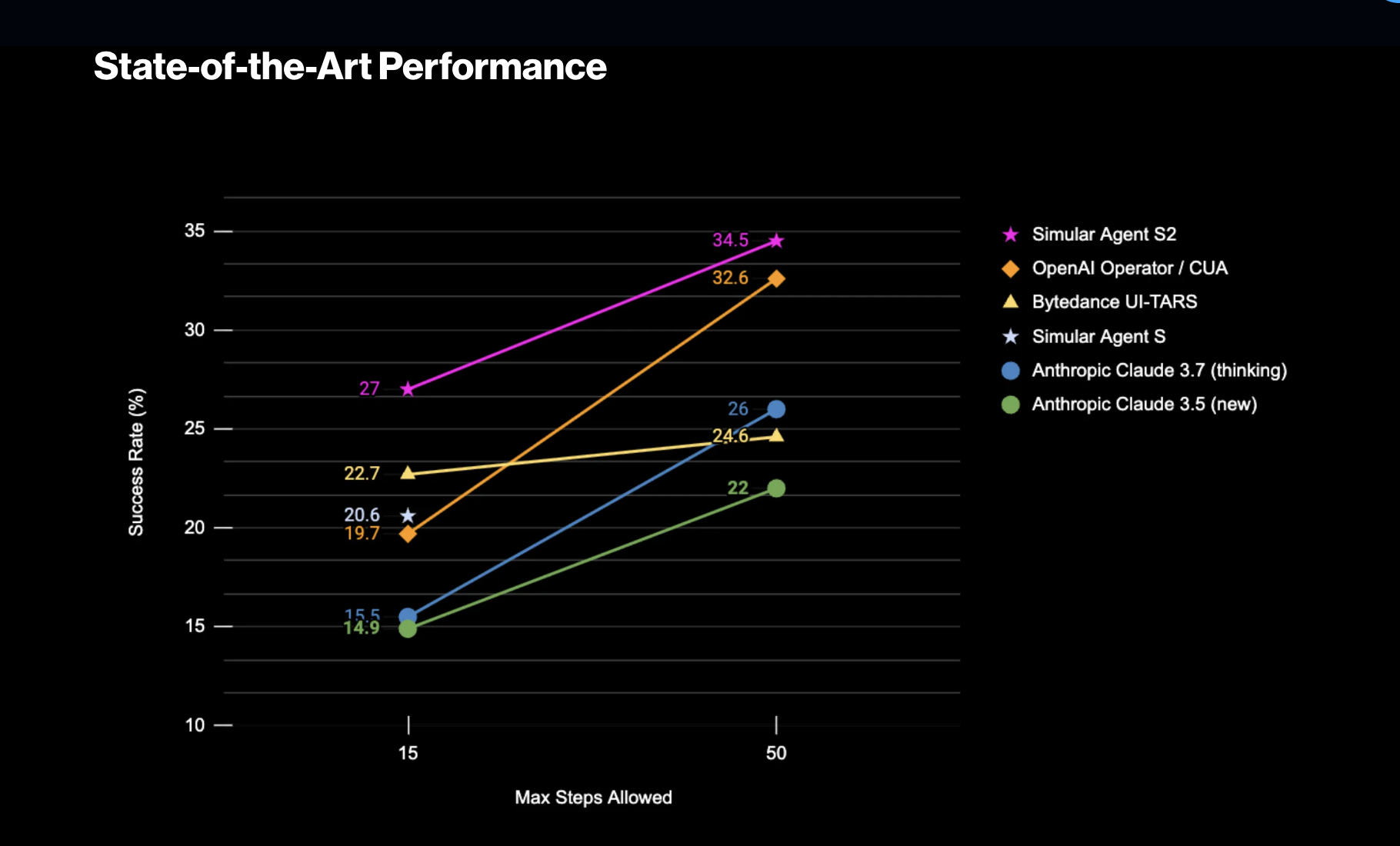
LLMs most impressive capabilities still revolve around generating text. But when it comes to navigating complex software interfaces or handling on-screen workflows, they need help. Here's where Simular's Agent S2 shakes things up/
Agent S2 is an open-source autonomous agent able to visually interpret and interact with user interfaces. Paired with n8n, a flexible open-source automation tool, Agent S2 can be orchestrated in workflows that tie together APIs, apps, and UIs. Obviously, Using this tools in combination can dramatically expand LLM's power and visibility.
What are the implcations?
Agent S2 is a new open-source framework that allows AI to interact with software like a human. It can see the screen, click buttons, and type. It also offers state-of-the-art performance in multi-step tasks, edging out OpenAI and Anthropic in benchmarks.
Beyond the stats, what sets it apart is how it learns: by breaking down tasks into sub-tasks handled by specialist modules and remembering what worked or didn’t. This dynamic knowledge base allows the agent to improve over time.
For marketers, this opens the door to real automation of complex workflows. It's not based on rule-based triggers, but performs adaptive action sequences that evolve.
Most companies today have plenty of documentation but not much content. They have pdfs, slide decks, and product manuals. Even case studies buried in download libraries that have yet to see daylight. It’s not that they don’t have answers; it’s that the answers are locked away, invisible to the LLMs people now use to ask questions.
It's a lost opportunity to generate greater brand visibility. Especially when it comes to answering middle-of-funnel questions.
It doesn't have to be this way. When it comes to client engagement, it might be helpful to stop thinking like SEOs and start thinking like machines. Google’s crawler and an LLM’s transformer are very different beasts. Google might index a PDF. An LLM will ignore it entirely. What to do?